Let’s have some fun, let’s break some servers.
I have a Virtualised Server (running under kvm on a CENTOS host) called node5. We are going to break it in different ways and
but first some housekeeping …
Hit like if you like this post and would like to see more like it, or follow to be kept informed of any new posts
Current Server Setup
O/S Level:
# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core)
Disk setup
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 918M 0 rom vda 252:0 0 8G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 7G 0 part ├─cl_node5-root 253:0 0 8G 0 lvm / └─cl_node5-swap 253:1 0 1G 0 lvm [SWAP] vdb 252:16 0 2G 0 disk └─vdb1 252:17 0 2G 0 part └─cl_node5-root 253:0 0 8G 0 lvm / vdc 252:32 0 1G 0 disk └─vdc1 252:33 0 1022M 0 part vdd 252:48 0 2G 0 disk vde 252:64 0 10G 0 disk └─vde1 252:65 0 50M 0 part
fdisk setup
fdisk output of /dev/vda (boot disk)
# fdisk -l /dev/vda Disk /dev/vda: 8589 MB, 8589934592 bytes, 16777216 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x86ba1170 Device Boot Start End Blocks Id System /dev/vda1 2048 2099199 1048576 83 Linux /dev/vda2 2099200 16777215 7339008 83 Linux
Scenario 1: Damaged grub configuration file
The linux16 lines control system boot. What we are going to do is damage the (non-rescue) linux16 line by changing it to linuxbuff. You can either do this directly using vi or by using sed
# vi /boot/grub2/grub.cfg
or
sed '0,/linux16/{s/linux16/linuxbuff/}' -i /boot/grub2/grub.cfg
Let’s check to see what’s been done
# grep linuxbuff /boot/grub2/grub.cfg linuxbuff /vmlinuz-3.10.0-862.el7.x86_64 root=/dev/mapper/cl_node5-root ro crashkernel=auto rd.lvm.lv=cl_node5/root rd.lvm.lv=cl_node5/swap console=tty0 console=ttyS0,115200n8 # grep linux16 /boot/grub2/grub.cfg linux16 /vmlinuz-0-rescue-f00f0b94583dbbc1433c9da0925b8e21 root=/dev/mapper/cl_node5-root ro crashkernel=auto rd.lvm.lv=cl_node5/root rd.lvm.lv=cl_node5/swap console=tty0 console=ttyS0,115200n8
So the default linux16 line has been corrupted but the rescue one is fine. So let’s reboot and see what happens
reboot
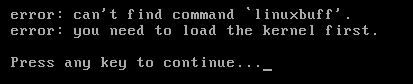
In the above case we know exactly what was done – so we could reboot, interrupt the boot process and then edit the grub boot config by entering e, changing the linuxbuff to linux16 and the booting with CTRL + X


But the above only works if you know EXACTLY what was wrong, and it is a simple fix. A better option would be too boot into rescue mode by scrolling to the last entry and pressing ENTER
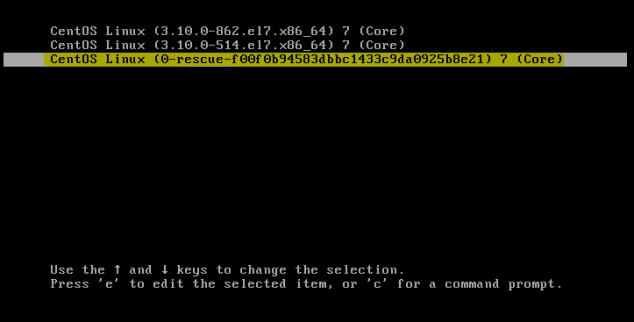
and then once booted – recreating the grub configuration file
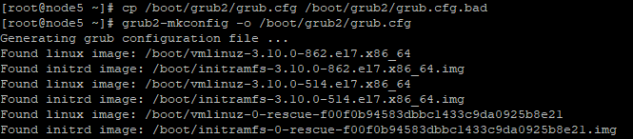
So let’s reboot and see what happens
reboot
Boom! a working system
Scenario 2: No grub configuration file
So this is one step worse than Scenario 1. Here there is no rescue option,
[root@node5 ~]# ll /boot/grub2/grub.cfg -rw-r--r--. 1 root root 5150 Nov 15 10:23 /boot/grub2/grub.cfg [root@node5 ~]# rm /boot/grub2/grub.cfg rm: remove regular file ‘/boot/grub2/grub.cfg’? y [root@node5 ~]# ll /boot/grub2/grub.cfg ls: cannot access /boot/grub2/grub.cfg: No such file or directory [root@node5 ~]# reboot
This causes the following issue when booting (or similar based on your host).

Now if you type out all the entries of the file the system will boot – but that’s not really feasible. What we have now is a non-booting system. To resolve we need a Bootable CD e.g. LiveCD or PXE boot. In my case I have attached a live CD and will boot from that
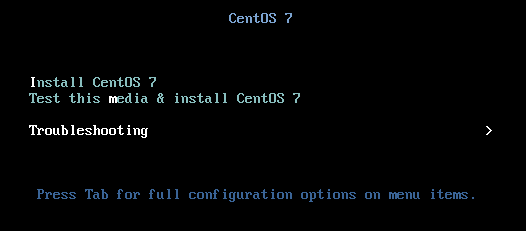
The live CD is also Centos 7 but it doesn’t match my exact version – which *should* be ok.
We are going to select the Troubleshooting Option and then Rescue a CentOS system, and finally select 1 to mount existing Linux Partitions


We then go through the standard process of remounting in rw mode and chroot, and finally running the same command as above
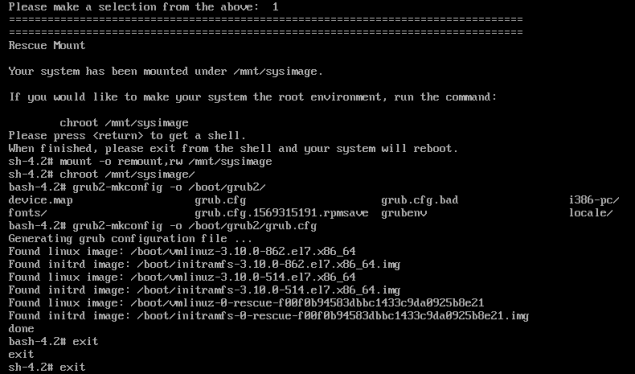
The system with automatically reboot (after entering exit twice, once for chroot and once for rescue mode)
Note: I did have some issues with a non-root disk that had a luksheader and a password that I could not remember – I dropped to a shell and cleared the partition on vde and retried
OK so we are back and running.
Scenario 3: Damaged MBR
Here we are going a step further, we are going to simulate a disk data corruption
# dd if=/dev/zero of=/dev/vda bs=4096 count=1 1+0 records in 1+0 records out 4096 bytes (4.1 kB) copied, 0.00228243 s, 1.8 MB/s # reboot
This has effectively wiped a portion of the MBR and will render the server non-bootable

So as there is no rescue mode, let’s boot from the CD again as we did last time. However this time it is not able to read from
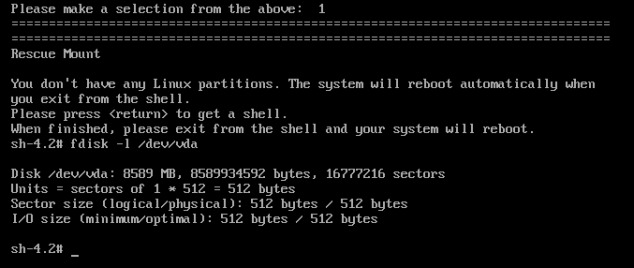
This is not so good. I couldn’t find a nice way of getting the system to recognise the partitions. Which still exist but MBR is damaged. So tried fdisk some new partitions that matched the old values (which luckily I still had)
fdisk /dev/vda
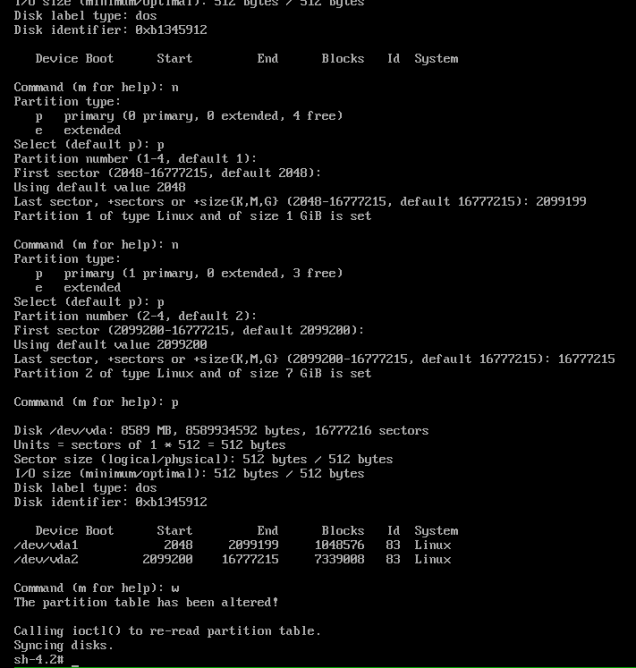
I ensured that I matched the values identically. It seems as though it had recognised the values. 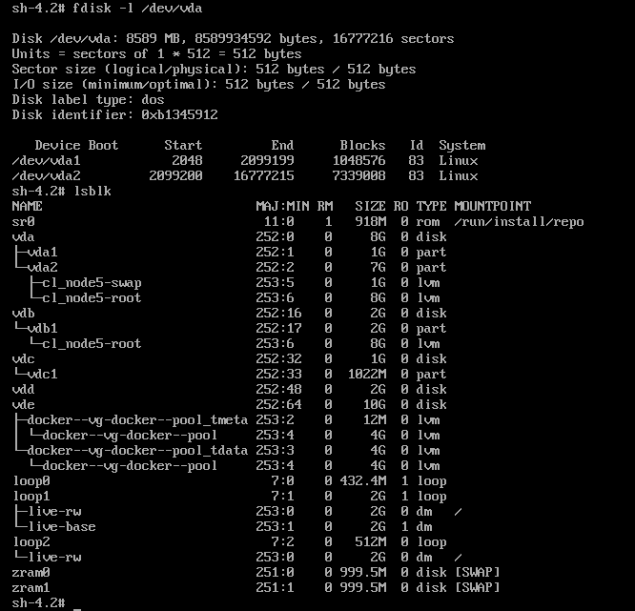
As can be seen above, it’s automatically set the first partition to swap and the second as root. Let’s reboot back into rescue mode and see if it picks up the partitions and replace grub boot loader.
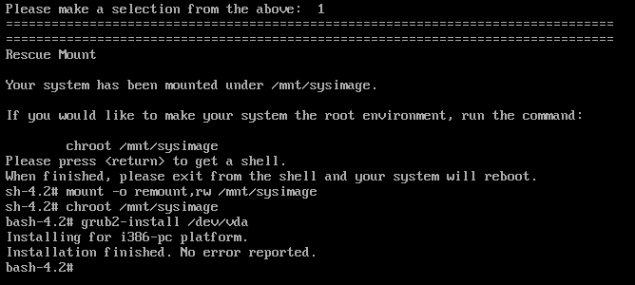
Time to reboot, BOOM! and we are back.
and finally …
Please let me know if you found this useful, I would love to hear your comments.
